If you are using someone else’s data, as we are now, our first task is to examine the structure and contents of the data set.
SPSS provides us with two tools for reviewing the contents of the data set: the Variables utility and the File Info utility which produces a data dictionary or code book listing of the data set. The Variables utility supports interactive checking about a variable during analysis. The File Info utility produces an output listing that can
be printed for reference.
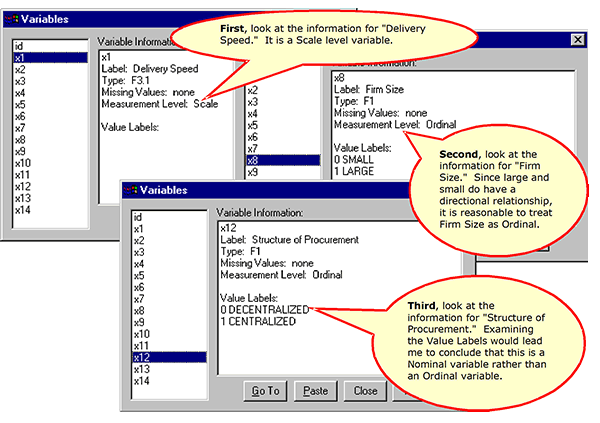
Both utilities list information about each variable in the data set: its mnemonic name, the text label for the variable, the measurement level of the variable, the labels for the different values if the variable is nonmetric, and the format that will be used for printing data for the variable, i.e. the number of decimal places displayed. The level of measurement, which is designated by the creator of the data set, can be a source of confusion because there are multiple terminologies for typing variables. Using the terminology of Hair, a variable is either metric or nonmetric. Metric variables include the traditional categories of interval level and ratio level variables. SPSS refers to metric variables as scale level variables. Hair’s nonmetric category includes the traditional measurement levels of ordinal and nominal. SPSS uses the traditional ordinal and nominal designation these variables.
Note that the default data type specified by SPSS is “Scale.” If the data set creator does not specify a level for each variable, or if the data set was created before SPSS supported typing of variables, the variable will be listed as “Scale.”
Metric variables include both continuous variables for which the measurement scale includes decimal values, and discrete variables only contain whole number measurements. Examples of continuous measurements are height, weight, temperature, etc. Examples of discrete variables include age, highest grade level attained, number of children, etc. Likert-scale scores are usually treated as discrete metric variables by convention, even though they are only designed to be ordinal scale.
The Data Dictionary
The data dictionary for a data set contains all the code book specifications for each variable: the mnemonic variable name, its associated text label, the measurement scale of the variable, as well as a list of codes for nonmetric variables.
The File Info Output
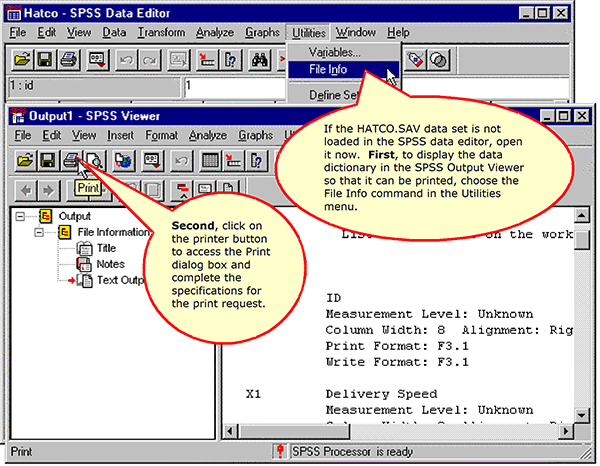
The Data Dictionary
The data dictionary information is written to the Output1 window in the SPSS Viewer. Scroll through the output. Can you identify the SPSS data type and the measurement level (metric or nonmetric) for each variable? Compare your answer to the listing in Table 1.3 in the text.
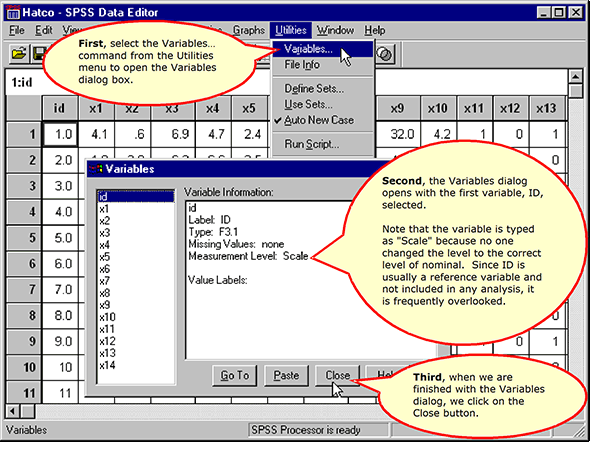
ID is included as a reference number so that we can refer back to the questionnaire for a specific subject if necessary. Only in very rare circumstances is it included in any analysis. If it should ever be used in an analysis, it is a label for the case and nonmetric by definition. We will get the additional information about our
variables in the next section.
ID is included as a reference number so that we can refer back to the questionnaire for a specific subject if necessary. Only in very rare circumstances is it included in any analysis. If it should ever be used in an analysis, it is a label for the case and nonmetric by definition. We will get the additional information about our
variables in the next section.
Online Information in the Variables Dialog Box
In addition to the complete listing in the data dictionary, information about each variable can be found in SPSS in the variables dialog box.
Accessing the Variables Dialog
Information about Other Variables
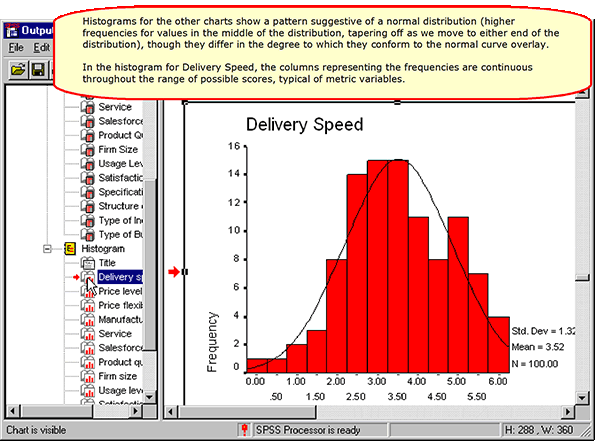
Previewing the Data with Frequencies and Histograms
Requesting Frequencies and Histograms
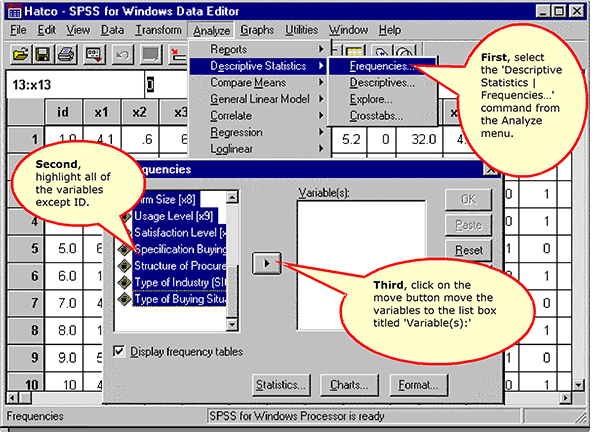
Request the Histogram Charts
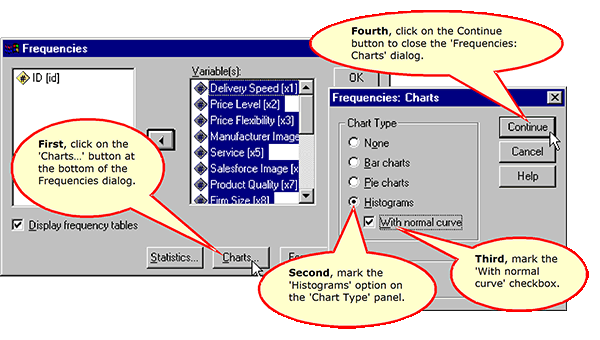
Request the Output
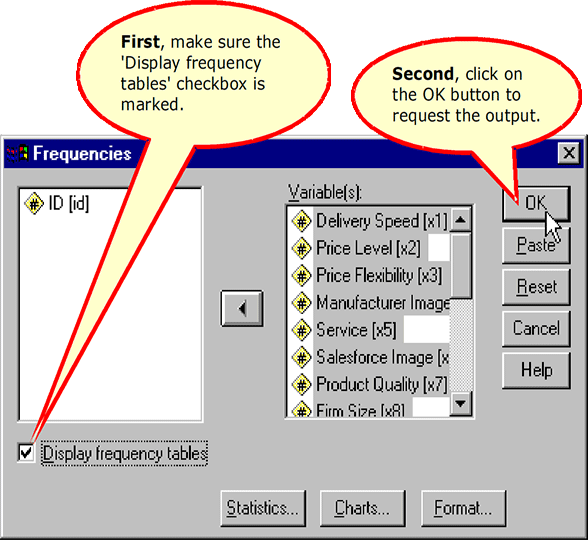
Viewing the Output
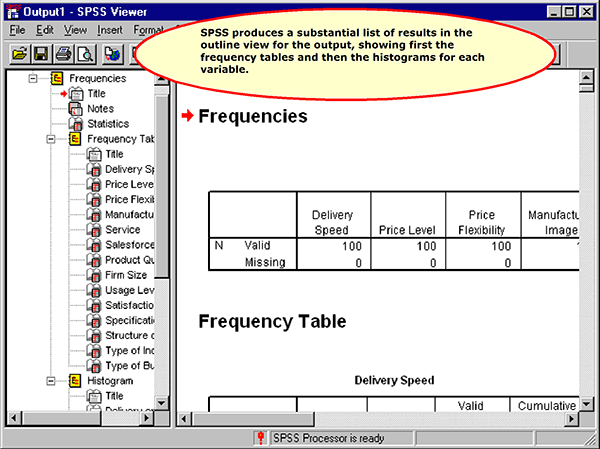
Histograms for Nonmetric Variables
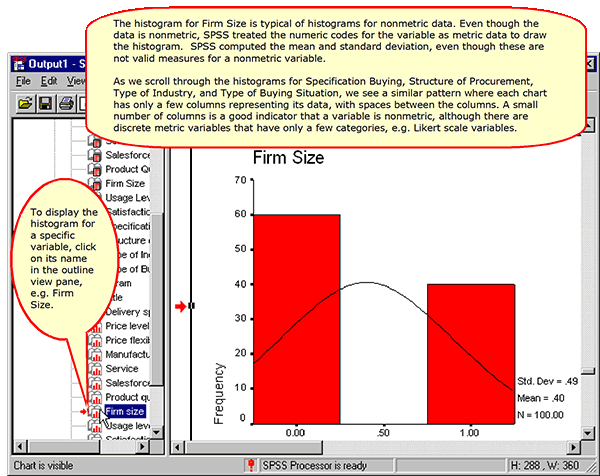
Histograms for Metric Variables